La reconnaissance visuelle distinguée par le Prix Longuet-Higgins
Permettre à un ordinateur de « voir » les images pour en reconnaître les motifs est un des objectifs de la vision par ordinateur. L’article "Beyond Bags of Features : Spatial Pyramid Matching for Recognizing Natural Scene Categories" de Svetlana Lazebnik, Cordelia Schmid et Jean Ponce vient d’être distingué du Prix Longuet-Higgins au cours de la Conference on Computer Vision and Pattern Recognition (CVPR) pour son impact sur ce domaine de recherche au cours des 10 dernières années. Retour sur cette publication, et perspectives sur les recherches menées aujourd’hui
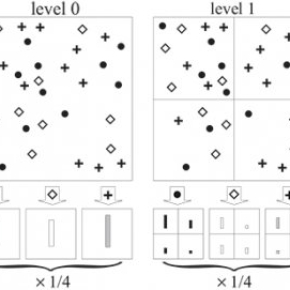
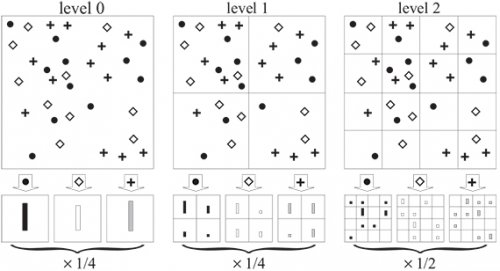
En vision artificielle, les objectifs sont principalement soit de permettre d’analyser de manière automatique le contenu des images numériques ou vidéos afin d’en extraire des informations tridimensionnelles pour en reconstruire un modèle 3D ; soit de reconnaître les objets qui sont présents sur ces images et vidéos. La publication "Beyond Bags of Features : Spatial Pyramid Matching for Recognizing Natural Scene Categories" s’est intéressée au domaine de la reconnaissance visuelle, auquel elle a apporté une amélioration significative. En effet, jusqu’en 2006, les méthodes étaient basées sur des « sacs de mots » (bag-of-features) qui découpaient une image en petits bouts pour réaliser des statistiques sur chaque portion. Mais la représentation spatiale de l’image était totalement laissée de côté : la représentation en histogrammes des informations sur l’image aurait été la même quel que soit l’ordre des pixels. Cet « oubli » de l’organisation spatiale était intéressant pour prendre en compte les changements de points de vue qui nécessite des invariants. Mais il y avait une perte d’informations du fait du manque de vision globale de l’organisation de l’image.
L’apport fondamental de la publication a été de réintroduire l’information spatiale en superposant sur l’image une grille pyramidale assez grossière (par exemple 16 carrés, puis 4, puis 1) pour voir comment les éléments se répartissent dans l’image. La pyramide spatiale permettait de prendre en compte des détails de l’image sur plusieurs niveaux de résolution, comme par exemple le fait de reconnaître une main sur une strate, et du coup une personne complète sur une strate supérieure de la pyramide. Cette méthode de reconnaissance des catégories de scènes a permis d’obtenir des taux de reconnaissance visuelle bien supérieurs à ceux qui existaient jusque-là, notamment dans la publication avec des exemples sur une large base de données de 15 catégories de scènes naturelles. Cette méthode est restée la meilleure en reconnaissance visuelle pendant plusieurs années, faisant figure de référence dans le domaine. Depuis, de nouvelles méthodes utilisant notamment l’apprentissage profond apportent des performances plus élevées, mais la méthode développée dans cet article de 2006 reste en quelque sorte « l’étalon » auquel il convient de se comparer.
En termes d’applications, au-delà des domaines classiques comme la surveillance ou l’industrie manufacturière qui font appel à la reconnaissance visuelle, de nouveaux domaines deviennent de plus en plus demandeurs. Les réseaux sociaux en ont besoin pour gérer le flux d’images des utilisateurs. Les voitures autonomes s’en servent afin d’analyser leur environnement et reconnaître ainsi les routes, piétons ou panneaux. La recherche dans ce domaine est donc particulièrement active en ce moment.
Une partie de l’équipe de Jean Ponce s’intéresse à l’apprentissage profond, qui permet une amélioration de la méthode de reconnaissance visuelle principalement par rapport à la nouvelle définition des descripteurs locaux. En effet, en 2006, le découpage local d’une image devait se faire à la main selon les principes des descripteurs SIFT de David Lowe. Aujourd’hui, l’apprentissage profond permet une définition automatique des descripteurs car les systèmes sont entraînés pour les circonscrire.
Mais un projet plus original intéresse la majorité de l’équipe. En effet, un des inconvénients des méthodes d’apprentissage supervisé, dont l’apprentissage profond, est qu’elles demandent une grande campagne d’annotations des images afin de pouvoir apprendre sur ces bases de données. Ces annotations sont extrêmement coûteuses en temps humain, et seront difficiles à poursuivre dans une période où les bases de données d’images deviennent de plus en en importantes. Pour aborder les méthodes d’apprentissage faiblement supervisés, les chercheurs ont essayé de minimiser l’effort d’annotation, en utilisant les métadonnées autour des images étudiées, comme par exemple les sous-titres d’un film pour les malentendants qui décrivent également les actions du film en plus des dialogues. Mais ils se sont aussi intéressés aux méthodes non supervisées. Ils ont en effet réalisé que le but des annotations était essentiellement de grouper ensemble des images qui se ressemblent. Plutôt que d’annoter 1000 photos avec la même identification, leur but est que l’ordinateur rapproche de lui-même les images qui se ressemblent pour que l’utilisateur n’ait qu’à vérifier et à nommer le groupe constitué automatiquement (comme par exemple des animaux). Un objectif par la suite serait même que l’ordinateur découvre automatiquement les annotations à affecter, par rapport aux informations qu’il pourrait trouver en ligne.
Publication : "Beyond Bags of Features : Spatial Pyramid Matching for Recognizing Natural Scene Categories" de Svetlana Lazebnik1
, Cordelia Schmid2
et Jean Ponce3
. In IEEE Conference on Computer Vision and Pattern Recognition, volume II, pages 2169-2178, 2006
- 1Department of Computer Science, University of Illinois at Urbana-Champaign. En 2006 : Beckman Institute University of Illinois
- 2Équipe-projet commune Inria THOTH et Laboratoire Jean Kuntzmann (LJK – CNRS/Grenoble INP/Université Grenoble Alpes)
- 3Département d’Informatique de l’École Normale Supérieure (DI ENS - CNRS/ENS/Inria) et équipe-projet commune Inria WILLOW. En 2006 : également au Beckman Institute University of Illinois