
Cédric Févotte, ERC Consolidator Grant 2015
Pour analyser des données matricielles, c’est-à-dire qui peuvent être organisées et stockées dans un tableau, il est souvent nécessaire de les décomposer en deux sous-tableaux dits “facteurs”. Les approches existantes trouvent souvent leurs limitations dans l’utilisation d’hypothèses statistiques simplificatrices ou encore dans l’utilisation de pré-traitements des données. Cédric Févotte, chercheur CNRS au sein de l’Institut de recherche en informatique de Toulouse (IRIT - CNRS/Université Toulouse 1/Université Toulouse - Jean Jaurès/Université Paul Sabatier/INP Toulouse), ambitionne de lever ces verrous dans le cadre de son ERC FACTORY (New paradigms for latent factor estimation).
Pour analyser des données matricielles, c’est-à-dire qui peuvent être organisées et stockées dans un tableau, il est souvent nécessaire de les décomposer en deux sous-tableaux dits “facteurs”. Les approches existantes trouvent souvent leurs limitations dans l’utilisation d’hypothèses statistiques simplificatrices ou encore dans l’utilisation de pré-traitements des données. Cédric Févotte, chercheur CNRS au sein de l’Institut de recherche en informatique de Toulouse (IRIT - CNRS/Université Toulouse 1/Université Toulouse - Jean Jaurès/Université Paul Sabatier/INP Toulouse), ambitionne de lever ces verrous dans le cadre de son ERC FACTORY (New paradigms for latent factor estimation).
![]()
Le traitement et l’analyse de ces données impliquent souvent de factoriser la matrice qui les représente. Cela signifie la décomposer, généralement de manière approchée, comme le produit de deux autres matrices, dits « facteurs ». Le premier, appelé parfois dictionnaire, est une sorte de concentré des échantillons du tableau de départ, dont on fait ressortir les caractéristiques (une « base » au sens large). Le second, dit matrice d’activation, indique quant à lui les coefficients de décomposition de chaque échantillon de données sur le dictionnaire. Cette décomposition correspond à une estimation dite de facteurs latents (latent factor estimation), sujet d’expertise de Cédric Févotte et cœur de son projet ERC.
Cette factorisation matricielle est utile dans plusieurs situations. La première est la réduction de dimension, liée en particulier au contexte du Big Data, et qui consiste à faire ressortir des informations clés d’un tableau de très grandes dimensions, afin d’en faciliter la manipulation. La matrice d’activation devient ainsi un résumé approximatif de la première matrice, une projection sur un espace de plus petite dimension que l’espace naturel des données.
Autre application, l’interpolation, pour compléter un tableau « à trous ». Votre fournisseur de vidéos à la demande, par exemple, se base ainsi sur les notes d’utilisateurs ayant aimé les mêmes films ou types de films que vous pour vous en recommander de nouveaux. Grâce à votre participation et celles d’autres spectateurs, ce filtrage collaboratif permet ainsi de prédire par interpolation les valeurs manquantes correspondant aux films non-visionnés dans la première matrice afin de recommander des films de manière efficace et anonymisée.
Enfin, la factorisation de matrices intervient souvent en séparation de sources. En traitement du signal audio, cela peut être par exemple utilisé pour restaurer ou remasteriser un enregistrement musical. Les méthodes de l’état de l’art, auxquelles Cédric Févotte a contribué, reposent sur le « dé-mélange » de spectrogrammes, procédé dans lequel on cherche à extraire les spectres « purs » des sources originales.
Dans le cadre du projet ERC FACTORY, l’objectif de Cédric Févotte est de proposer de nouveaux paradigmes qui vont repousser les frontières de la décomposition matricielle pour l’analyse de données. En effet, l’existant se bute parfois à des frontières de faisabilité.
Un premier objectif concerne la modélisation probabiliste des données et la question notamment du « bruit ». Le bruit est en effet inhérent à l’acquisition de données. On l’imagine facilement sur un enregistrement audio ou une image hyper-spectrale de la Terre, mais il existe dans tous types de données, comme par exemple lorsque des utilisateurs notent de façon imprécise voire au hasard des films qu’ils ont visionnés ou des produits qu’ils ont achetés. Les chercheurs ont longtemps formé des hypothèses simplificatrices sur la nature du bruit, afin de rendre les problèmes d’estimation afférents plus aisés. Mais ces hypothèses peuvent en contrepartie nuire à la qualité de la factorisation. Aussi, Cédric Févotte souhaite développer de nouveaux estimateurs pour des modèles de bruit plus respectueux de la nature des données.
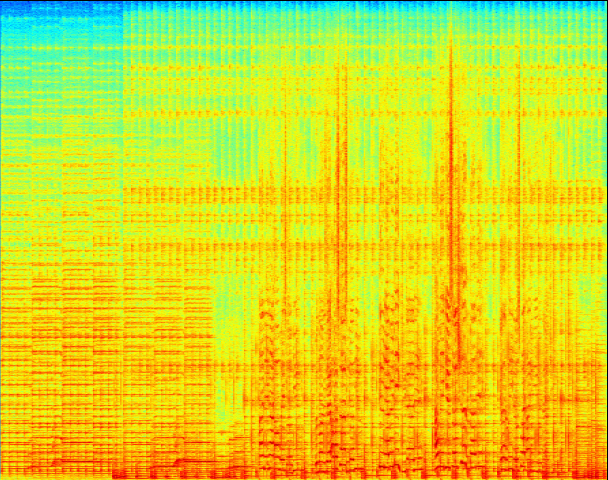
Il recherche également à s’affranchir du pré-traitement qui est généralement fait sur les données brutes. En effet, celui-ci induit un biais qui limite les performances de la factorisation. En traitement du signal audio par exemple, les données brutes (ici, la forme d’onde du signal temporel) sont pré-traitées via le calcul d’un spectrogramme, qui découpe le signal en segments de quelques centièmes de secondes pour en faire une analyse spectrale. Cette transformation « temps-fréquence » nécessite le réglage de paramètres « à la main » (comme la taille des segments et le type d’analyse spectrale). Dans ce cas-là et dans d’autres, Cédric Févotte propose un cadre d’apprentissage en amont pour que la transformation optimise la précision de la factorisation en aval.
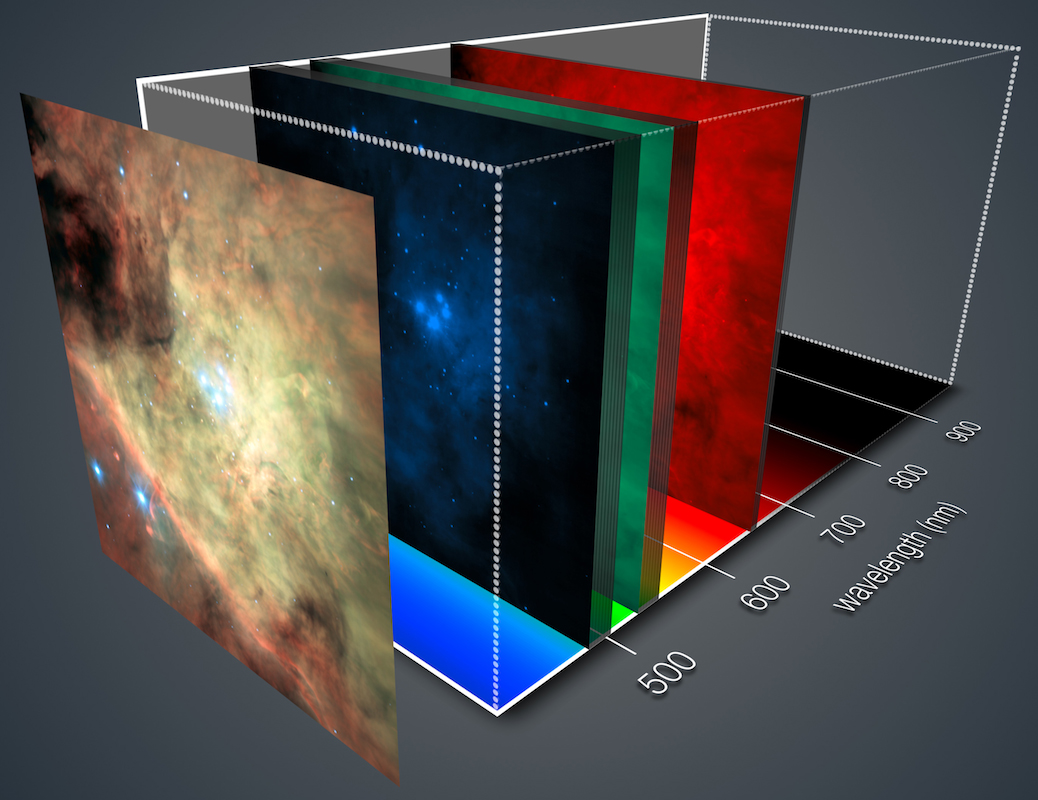
Les domaines d’application privilégiés par Cédric Févotte dans le cadre du projet FACTORY sont l’analyse spectrale en traitement du signal audio et en télédétection pour l’observation de la Terre ou de l’Univers. Il s’intéresse également à la fouille de données hétérogènes ou « multi-modales », comme par exemple un jeu de données qui contiendrait des descripteurs musicaux de chansons mais aussi des notes d’auditeurs, les textes des chansons, etc., avec des approches reposant sur des techniques de co-factorisation.