
Combiner les meilleurs filtres pour lire l’invisible
Savoir détecter le degré de sécheresse d’une zone agricole, l’organisation de l’espace urbain dans un territoire ou encore déterminer les routes utilisables suite à une catastrophe naturelle, ces analyses d’images sont possibles grâce aux traitements d’images hyperspectrales. Mais le choix de l’analyse se faisait jusque-là manuellement. Une publication, distinguée comme le meilleur article de la période 2012-2015 paru dans la revue International Society for Photogrammetry and Remote Sensing (ISPRS), propose un algorithme pour analyser automatiquement de façon optimale ces images. Retour sur la résolution de cette problématique.
Les images prises par satellite sont appelées images hyperspectrales, c’est-à-dire qu’au lieu d’enregistrer « seulement » trois composantes colorimétriques, qui correspondent à trois longueurs d’onde de la lumière, on va échantillonner le spectre lumineux de manière beaucoup plus dense. L’échantillonnage est beaucoup plus fin, donnant ainsi plusieurs centaines de longueurs d’ondes lumineuses par zone analysée. Cela permet de donner de très nombreuses informations supplémentaires… mais qui ne sont pas visibles par l’œil humain. Il est donc essentiel de savoir extraire les informations de ces images hyperspectrales.
L’apport de la publication Multiclass feature learning for hyperspectral image classification : Sparse and hierarchical solutions est de proposer pour la première fois un algorithme automatique de traitement des images hyperspectrales, sachant déterminer et combiner de façon optimale les différents filtres d’analyse possible.
L’objectif de l’analyse des images hyperspectrales est de pouvoir déterminer automatiquement la nature des zones observées : quel type d’occupation des sols, s’il s’agit d’immeubles, de routes, d’une végétation et dans ce cas-là de quel type… Pour cela on réalise une classification supervisée, c’est-à-dire que sur une image on applique des étiquettes sur des éléments identifiés, et l’on souhaite généraliser cette analyse à l’ensemble de l’image. Mais pour classifier chaque pixel, il est nécessaire d’appliquer des filtres permettant de faire ressortir différentes caractéristiques.
Traditionnellement, les experts qui analysent ces images savent quel filtre utiliser pour extraire tel type d’informations. Mais il était rare d’appliquer plusieurs filtres successifs, la combinaison de différents niveaux de filtrage faisant appel à des questions de combinatoire impossible à gérer par un humain. C’est précisément ce que propose l’algorithme présenté dans cette publication.
En sélectionnant au hasard un ensemble de pixels et un filtre, l’algorithme traite l’image et voit si le résultat apporte un ajout d’informations ou non. À chaque itération, l’algorithme compare si l’incrément de nouvelles informations est suffisant par rapport à d’autres tests, et ne garde que les plus pertinents qu’il combine encore ensemble. Il explore ainsi un arbre de possibilités, qui bien qu’aléatoire, donne les meilleurs résultats possibles à l’heure actuelle. L’algorithme va piocher les différents filtres qu’il va essayer dans une sélection que les experts auront déterminée comme les plus pertinents. À partir d’un ensemble de filtres de base, et en les combinant entre eux, l’analyse permet ainsi de faire apparaître des informations extrêmement riches des images hyperspectrales. L’algorithme fournit la succession de filtres la plus pertinente, ce qui permet de décomposer si on le souhaite les filtres appliqués et leur ordre.
Grâce à cette méthode d’apprentissage statistique originale, les chercheurs souhaitent extraire automatiquement les meilleures représentations des pixels de l’image hyperspectrale, et prendre également en compte des informations complémentaires comme la hauteur des sols.
Comme on peut l’imaginer, les applications de ce type d’analyse sont nombreuses, notamment pour la surveillance de l’environnement. Cela permettrait ainsi, sur des projets à long terme, que les politiques locales aient une meilleure compréhension de leur territoire, en connaissant finement et de façon actualisée quel pourcentage de terre est consacré à la culture, l’évolution du milieu urbain avec la répartition entre immeubles et maisons. Mais cela pourrait également être une aide précieuse en cas de gestion de désastres, pour déterminer les accès possibles à une zone, calculer le pourcentage de destruction par zones pour ainsi savoir où concentrer les secours.
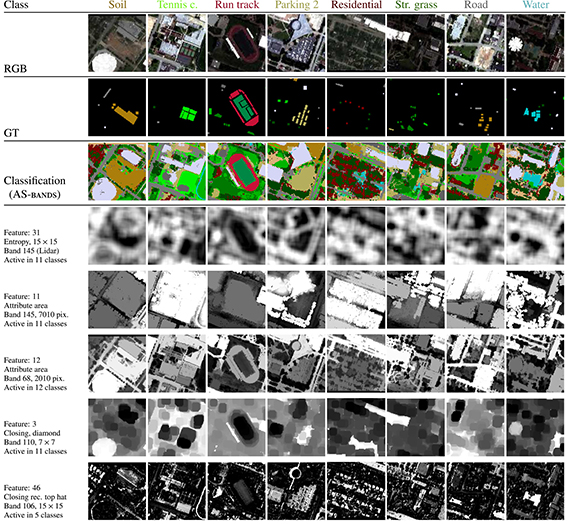
Publication : Multiclass feature learning for hyperspectral image classification : Sparse and hierarchical solutions de Devis Tuia1 , Rémi Flamary2 et Nicolas Courty3
- 1Department of Geography, University of Zurich, Switzerland
- 2Laboratoire J-L. Lagrange (CNRS/Observatoire de la Côte d’Azur/Université Nice Sophia Antipolis)
- 3Institut de recherche en informatique et systèmes aléatoires (IRISA - CNRS/ENS Rennes/Inria/INSA Rennes/Institut Mines-Télécom/Université de Bretagne-Sud/Université de Rennes 1)